我也谈谈排序
排序是算法最基本的一个,但我的文章除了在算法本身外还想聊聊别的,从计算机的视角去看看有何启发。
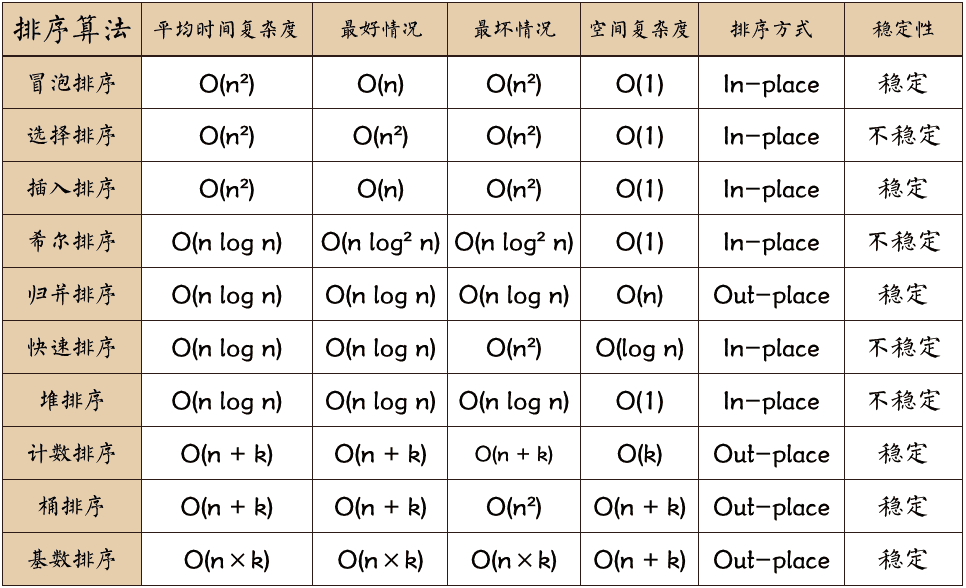
注意希尔排序的时间复杂度应该是 O(n^(1.3—2))
上图中,最常用的算法是一种叫做“快速排序”的算法,由英国计算机科学家托尼霍尔(Tony Hoare)在1959年想到,1961年发表的,他因此获得爵士头衔。第一台计算机 ENIAC 1946年发明到这个算法的提出,计算机科学花了十多年的时间才得到了一个好的排序算法,此后这种算法的改进版和不同情况下优化的版本也层出不穷。
接下来就依次讨论一下这些算法
冒泡排序:每次都会将未排序列表中数值最大的数字移动到末端,顾名思义冒泡排序。
void bubble_sort(int* arr, int len)
{
int i, j;
for (i = 0; i < len; i++)
{
for (j = 0; j < len - i - 1; j++)
{
if (*(arr + j) > *(arr + j + 1))
{
exchange(arr, j, j + 1);
}
}
}
}选择排序:每次从未排序列表中选择出一个最大的值放到末端。顾名思义选择排序。
void select_sort(int* arr, int len)
{
int i, j, max;
for (i = len - 1; i >= 0; i--)
{
max = 0;
for (j = 1; j <= i; j++)
{
if (*(arr + max) < *(arr + j))
{
max = j;
}
}
exchange(arr, max, i);
}
}插入排序:在左侧维护一个有序列表,每次从右侧取一个插入到左侧的有序列表中,顾名思义插入排序。插入排序在最好的时候,只需要经过n-1次排序即可,发生这种情况是数组自身已经是一个有序数组了。所以,插入排序在处理数据有序度比较高的数据时有独特的优势,但从通用排序的情况下来看,这个算法是O(n^2)。
void insert_sort(int* arr, int len)
{
int i, j;
for (i = 1; i < len; i++)
{
j = i;
while (j > 0 && *(arr + j) < *(arr + j - 1))
{
exchange(arr, j, j - 1);
j--;
}
}
}希尔排序: D.L.Shell于1959年提出,直到目前也没有人可以用数学证明写出希尔排序的时间复杂度是多少。但总体来说优于冒泡、选择、插入,有学习意义,但是已经没有实用价值。希尔排序的是先通过插入排序让列表局部变得相对有序,最后再完成所有排序,由于插入排序的性能是O(n^2),因此分治之后解决每个小问题的速度快了很多,最后完成整体排序时数组已经基本有序了,对一个基本有序的数组排序正好符合插入排序最优解的特殊情况 (希尔排序和插入排序在10w无序数组排序时性能有近千倍差异,因为希尔排序大约是O(n^1.5)) 。希尔排序带给了人们一种思路,当我们看到一种算法有问题时,可以通过其他方法来改进,通常会有效果。
//注意:当h变为1时,相当于执行了一次插入排序算法
void shell_sort(int* arr, int len)
{
int h, i, j = 1;
h = 1;
while(h < len / 3)
{
h = 3 * h + 1;
}
while(h >= 1)
{
for (i = h; i < len; i++)
{
for(j = i; j >= h; j -= h)
{
if (arr[j] < arr[j - h])
{
exchange(arr, j, j - h);
} else {
break;
}
}
}
h /= 3;
}
} 归并排序:归并排序是一种分治思想的应用,吸引人的 n logn复杂度相比于前几种算法有了很大的提升,可以分为两种方式
1、自顶向下:即将数组一分为二,然后再分,直到只有一个元素为止。通过递归的方式实现,需要注意递归的深度可能导致栈溢出。
2、自底向上:这看起来更像是自顶向下的一个迭代版本写法,好处不言而喻,它去掉了递归,更以后利于工程实现。
void array_merge(int* arr, int lo, int mid, int hi)
{
if(lo >= hi)
return;
int i = lo;
int j = mid + 1;
int tmp[hi - lo + 1];//存放临时结果
while(i <= mid || j <= hi)
{
if (i > mid)//前半段已经用完
{
while (j <= hi)
{
tmp[j - lo] = *(arr + j);
j++;
}
break;
}
if (j > hi)//后半段已经用完
{
while (i <= mid)
{
tmp[(hi - mid) + (i - lo)] = *(arr + i);
i++;
}
break;
}
//较小的数字进入临时数组
if (*(arr + i) < *(arr + j))
{
tmp[(j - mid - 1) + (i - lo)] = *(arr + i);
i++;
} else {
tmp[(j - mid - 1) + (i - lo)] = *(arr + j);
j++;
}
}
//copy到原数组
memcpy(arr + lo, tmp, (hi - lo + 1) * sizeof(int));
}
//自顶向下,通过递归方式完成
void up2Down(int* arr, int lo, int hi)
{
if (lo >= hi)
{
return;
}
int mid = lo + (hi - lo) / 2;
up2Down(arr, lo, mid);
up2Down(arr, mid + 1, hi);
array_merge(arr, lo, mid, hi);
}
//自底向上,通过迭代方式完成
void down2Up(int* arr, int len)
{
int k, i;
for(k = 1; k < len; k*=2)
{
for (i = 0; i < len - 1; i += 2 * k)
{
array_merge(arr, i, i + k - 1, i + 2 * k - 1 > len - 1 ? len - 1 : i + 2 * k - 1);
}
}
}
快速排序:快排在时间复杂度上和归并排序是在一个量级的,同一个量级的算法还有一些,但是为什么快排成为了最终赢家呢?因为相比归并排序,多数情况下快排要比归并快2倍。通过代码你可以发现快排的比较次数相对更少。
void partition(int* arr, int lo, int hi)
{
if (lo >= hi)
return;
int pivot, i, j;
pivot = *(arr + lo);
i = lo + 1;
j = hi;
while (i <= j)
{
if (*(arr + i) <= pivot)
{
exchange(arr, i, i - 1);
i++;
} else {
if (*(arr + j) > pivot)
{
j--;
} else {
exchange(arr, j, i);
j--;
exchange(arr, i, i - 1);
i++;
}
}
}
partition(arr, lo, i - 2);
partition(arr, i, hi);
}三向切分快速排序:Dijkstra的杰作,这是对于快速排序的一个改进版本,可以看到快速排序虽然快,但是如果输入有大量重复的数字时,性能还可以提升,最快可以提升到O(n)。如果不考虑短数据输入以及其他特殊情况,在通用排序算法里面三向切分算法已经近乎最优,也是Java底层Map类型的实现算法之一。
void three_partition(int* arr, int lo, int hi)
{
if (lo >= hi)
return;
//选取第一个作为枢值
//warning 枢值的选取在实际应用中需要有所考究,应该尽量随机,否则在特殊情况下排序性能会急剧下降,甚至作为被人利用的漏洞
int pivot = *(arr + lo);
int i, lt, eq, gt;
lt = lo;
eq = lo + 1;
gt = hi;
while(eq <= gt)
{
if (*(arr + eq) < pivot)
{
exchange(arr, eq, lt);
eq++;
lt++;
} else if (*(arr + eq) == pivot)
{
eq++;
} else {
if (*(arr + gt) < pivot)
{
exchange(arr, gt, eq);
gt--;
exchange(arr, eq, lt);
eq++;
lt++;
} else if (*(arr + gt) == pivot)
{
exchange(arr, eq, gt);
gt--;
eq++;
} else {
gt--;
}
}
}
three_partition(arr, lo, lt - 1);
three_partition(arr, eq, hi);
}堆排序:特殊之处在堆排序将一个连续的数组抽象成为了一个堆结构(类似树结构,非二叉树。所有父节点比子节点大,所有子节点比父节点小),通过维护堆的完整最终达到排序的目的, 堆排序据说在一些古老的系统里面使用较多因为不使用递归(防止栈溢出),而且实现简单,但是堆排序的一个缺点是无法用到缓存,因为堆排序造成了大量的随机内存读取,所以工程上的实际表现情况可能会更糟糕一些。
//堆排序 注意为了计算方便,输入数组从下标 1 开始计数
void sink(int* arr, int k, int len)
{
if (2 * k <= len)
{
int max = 2 * k;
if (2 * k + 1 <= len)
{
if (*(arr + 2 * k + 1) > *(arr + 2 * k))
{
max = 2 * k + 1;
}
}
if (*(arr + max) > *(arr + k))
{
exchange(arr, k, max);
sink(arr, max, len);
}
}
}
void head_sort(int* arr, int len)
{
//初始化堆
int k, i;
k = len / 2;
for (k = len / 2; k >= 1; k--)
{
sink(arr, k, len);
}
//置换元素
while(len > 1)
{
exchange(arr, 1, len);
len--;//缩减堆的规模
sink(arr, 1, len);
}
}
计数排序:如果有人说 O(n logn) 是排序性能的极限了,这时候你可以反驳,还有O(n)的算法。其实他说的也没错,O(n logn)确实是排序的性能极限,不过需要指出O(n logn)是基于比较的通用排序的极限,在应对一些特殊情况的时候,还有更好的办法。例如在数据的值范围有限的情况下,比如对人的年龄进行排序。计数排序本质上是利用了被排序数据的特性对数据做了压缩,需要指出的是计数排序需要消耗更多的空间。注意,此处的计数排序并不稳定,因为被排序内容为数字,如果需要一个稳定的计数排序可以参考桶排序中的计数排序。
int count_sort(int arr[], int len, int max, int min)
{
int count = max - min + 1;//取值范围
int list[count];
int i, j, k;
//初始化
for (i = 0; i < count; i++)
list[i] = 0;
for (i = 0; i < len; i++)
list[arr[i] - min]++;//计数排序
//输出回原数组
k = 0;
for (i = 0; i < count; i++)
{
for (j = 0; j < *(list + i); j++)
{
arr[k] = i + min;
k++;
}
}
}桶排序:其核心思想是讲数据分配到不同的桶中,例如 0-19, 20-39, 41 – 60 …,通过值的范围进行分组,每个组就是一个桶,将数据先归纳到各个桶中,然后对每个桶分别进行排序。算法的性能受到每个桶取值范围的影响,好的情况下每个桶的数据量都是均匀的,而最差的情况下只有一个桶有数据。与归并排序有异曲同工之妙。
基数排序:其核心思想是不再将一个数字看做为整体,而是把数字看做由个、十、百、… 不同的位组成的值,通过对数字每个位进行比较,完成排序的目的。但是反直觉的是,基数排序先从低位(个位)开始排序,然后再对高位排序。
int radix_sort(int* arr, int len)
{
//获取最大的数字位数
int max, i, bit;
max = arr[0];
for (i = 1; i < len; i++)
{
if (arr[i] > max)
max = arr[i];
}
bit = 1;
while (max > pow(10, bit))
bit++;
int tmp[len];//临时数组
int count[10];//当前计数器
int mod;//当前取模数
int j;
for (i = 0; i < bit; i++) //对每一个位分别处理
{
mod = pow(10, i);
//计数器初始化
for(j = 0; j < 10; j++)
count[j] = 0;
//计算分区位置
for(j = 0; j < len; j++)
count[(arr[j] / mod) % 10]++;
//计算每个分区在结果中的起点下标
int pre = count[0];
count[0] = 0;
for(j = 1; j < 10; j++)
{
pre += count[j];
count[j] = pre - count[j];
}
//结果输出到tmp
for (j = 0; j < len; j++)
tmp[count[(arr[j] / mod) % 10]++] = arr[j];
memcpy(arr, tmp, len * sizeof(int));//tmp向arr赋值
}
}排序算法学习有感:
如何减熵:
热力学第二定律指出,一个封闭的系统是熵增的过程,会变得无序,而打破这个系统需要引入信息,使其回到有序的状态。那么我们可以把一堆等待排序的数字看做成为一个无序封闭系统,现在需要通过算法为其减熵,如果要满足效率最优,我们需要考虑到内外部因素充分利用已有的信息来达到减熵的目的。
比如,一堆很多,而且无序度很高的数字,如何减熵呢?
完全没有信息,使用快速排序算法 O(n log n) 。
现在告诉你,虽然数字多,里面也有不少重复的,如何减熵呢?
利用有重复数字的信息,三向切分算法 O(n log n) ,针对重复数字进行优化,最好时(几乎全是重复的)可以优化到 O(n)。
如果告诉你,对全世界所有人的年龄进行排序,如何减熵呢?
利用年龄意味着数据范围是很有限的信息,年龄通常在0-150之间,使用计数排序法,时间复杂度为 O(n)。
如果告诉你,要排序的数字通常在10个以内,偶尔才会有较多的数字需要排序,如何在工程上提高排序速度呢?
利用通常10个以内的信息,对数组的长度做先行判断,以PHP源码的sort函数为例,长度在5个及5个以内通过直接if else穷举每种情况比对,长度在6个到16个之间采用插入排序算法(改进版的插入排序),在16个以上时,使用快速排序(改进版的快速排序)。
利用一切已知信息配合算法进行减熵,通过选择不同的算法从计算机科学意义上来讲,效率能获得量级的提升。从工程的角度来看,以PHP源码的sort函数为例,在充分的利用了各种信息之后,又针对不同的情况应用更复杂的组合可以在前者的基础上再获得一些提升,这对于工程意义也是很大的。
做事效率:
在上面的各种排序算法中,复杂度从O(n^2) -> O(n log n)->O(n),算法历经了三次量级上的速度提升。在这三次提升当中可以明显的看到,其实算法只在做一件事情,那就是少做无用功。
从O(n^2) -> O(n log n)是通过算法方案的改进来实现的,而O(n log n)已经是数学上可以证明的,排序速度的极限了,为什么还能在某些情况下做到 O(n) 呢?因为,O(n log n) -> O(n) 的提升是利用了数据本身的已知信息来大幅减少算法要做的事情,自己少做事借助已有的外力达到目的,可以用O(n)为什么要O(n log n)呢?
站在前人的肩膀上进步:
这个是和同事赵亮讨论时想到的,掌握科学的做事方法,获得叠加式进步的重要性。在一些传统行业或者不可叠加进步的行业里面,比如厨师,中医等,很少有谁能说自己的厨艺,医术能够超过百年前的某位名厨、名医。而在IT、物理学、数学、医学等现代科学领域,在短短的几百年间就取得了惊人的成就,因为它们使用了科学的方法不断取得叠加式的进步,比如计算机科学花了十几年才找到的快速排序方法,今天大学课堂上可能一节课不到就讲完了,今天的一个智能手机计算机能力可以超过几十年前放满一屋子的超级计算机,几百年前在欧洲最先进的思想“日心说”,“万有引力”在今天只是初中课堂上的 Common sense…。
农耕文明时期人和人的差距在1个数量级以内,即最能干活儿的人也抵不过10个普通人。到了工业文明这被放大到了1到2个数量级,即1个工业国工人的生产能力是农业国工人的10到100倍,而到了信息文明,从上面的排序算法O(n^2) -> O(n log n) -> O(n) 可以看出差距被拉大到了数以万倍还多。
想要获得更大成就必须要通过学习先进的思想,工作方法,叠加式进步。如同这十个排序算法一般,看似简单但却是了计算机科学花了一二十年才总结出来的精髓。
一些疑问:基数排序 VS 快速排序
通过我的实际测试基数排序在很多时候确实要优于快速排序一些。为什么今天世界主流是快速排序而非基数排序呢?
快速排序将性能提升到了基于比较的算法的极限O(n log n),这是基于比较的通用排序性能的极限。同时快速排序也非常有利于工程实现,可以很好的利用到CPU的三级缓存。
基数排序的发明可以追溯到1887年赫尔曼·何乐礼在打孔卡片制表机(Tabulation Machine)上的贡献,其原理是利用数字的特性将问题拆解成了有限问题,对每一个位进行计数排序,这样只需要经过最长位次数的计数排序就可以完成。作为一种通用排序其时间复杂度为 O(n * k),这里的k是最大数字的宽度,如果将k作为一个常数省略的话,会得到一个惊人的结果 O(n)。在实际的测试中也发现基数排序相比于快速排序有明显的优势(使用c语言生成100w随机数测试)。基数排序在应用上的缺点主要有以下两个方面
1、CPU缓存利用不如快速排序
2、占用更多的空间
不过IT产业最近十几年的发展趋势对于基数排序来说是更有利的,最近十几年呈现了以下两个趋势
1、CPU主频提升接近停滞(发展多核),内存频率提升明显,CPU和内存的频率差距缩小
2、内存越来越大
趋势1的原因,这可能是我测试基数排序优于快速排序的原因,这部分缺点被最近十几年的IT产业发展给抵消掉了一部分。据悉,在超级计算机中好像都在使用基数排序了。此外这篇知乎讨论的文章可作为参考。