图的存储
图的几个概念:
顶点:树中的元素称为节点,而图中的元素称为定点
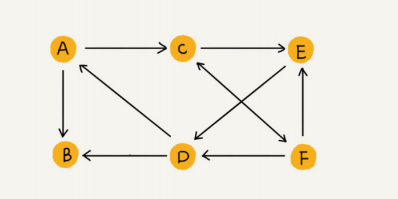
有向图:顶点之间关系是有方向的,例如微博关注,被关注
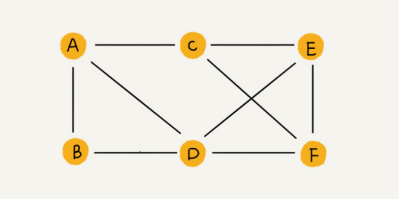
无向图:定点之间的关系是没有方向的,例如社交好友
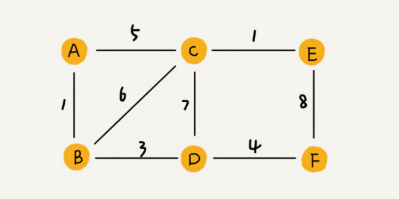
带权图:关系具有权重属性,例如QQ亲密度
边:一个顶点与其他顶点之间建立连接的关系
度:顶点相接的边的条数
入度:有向图中,有多少条边指向这个顶点
出度:有向图中,一个顶点指向多少个其他顶点
图的存储方式:
邻接矩阵存储方法:
这是一种比较直观的存储方法,简单来说就是一个二维数组。假设有顶点a和顶点b,如果a和b之间有边,对于无向图设定arr[a][b], arr[b][a] 的值为1就可以了,如果是有向图,a指向b则设定arr[a][b]值为1,b指向a则设定arr[b][a]值为1。如果是带权图,则存储的值为权重。
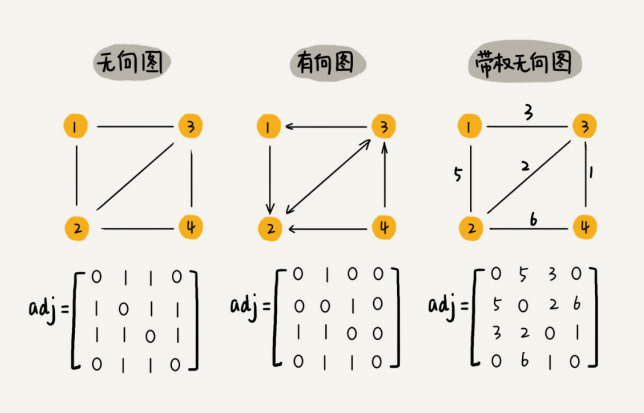
可以看出来,邻接矩阵对于空间的消耗是非常大的,需要N^2 的空间才能存储。邻接矩阵对于空间的浪费主要来自以下两个方面:
1、存储稀疏图,比如微信好友,有上亿个顶点但是每个顶点只有几百条边,是非常浪费的,大量的空间被闲置了。
2、存储无向图,无向图中arr[a][b]和arr[b][a]的值是等价的,理论上只需要将矩阵从对角线切开存储一半就可以了。
3、无法存储过大的数据量,例如存储1亿个用户关系,如果按照一个id 4字节计算需要36,379TB的存储空间,显然是无法接受的。如果达到微信爸爸10亿用户的规模,这个数组还要乘以100。
邻接矩阵存储的优势也是明显的,存储方式简单,查询速度快,计算方便,可以将图的运算转换为矩阵的运算。
邻接表存储方法:
这个长得有点像哈希表的存储结构就是邻接表存储法,定义一个数组,每个数组延伸一个扩展的数据结构(链表,跳表,红黑树…视数据量和业务方向而定)去存储对应的关系。这弥补了邻接矩阵浪费存储空间的缺点,但是又有了新的问题,如下图如果要查询节点4的出度很容易,但是要查询节点4的入度就很困难了,要遍历其他所有的链表。
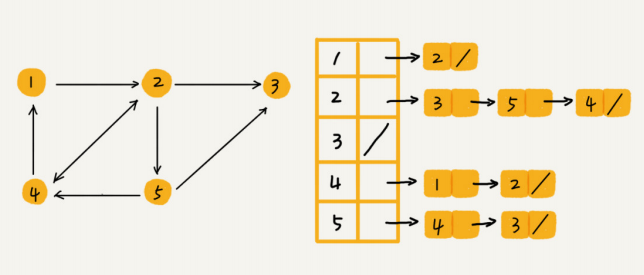
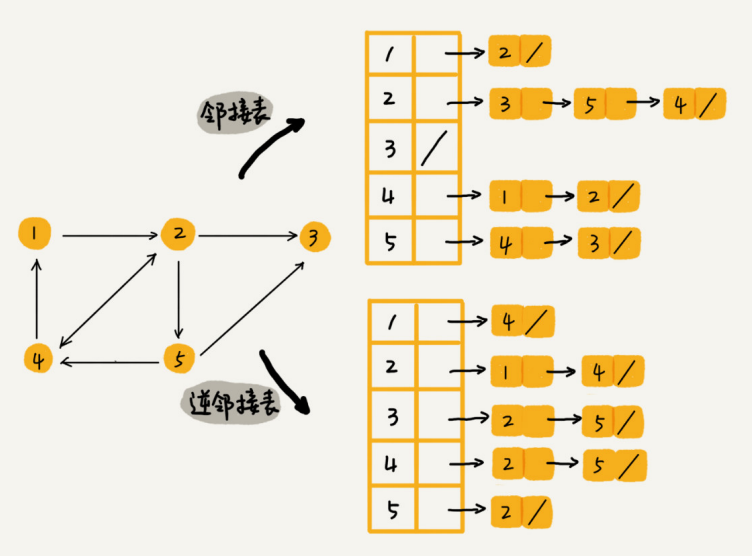
针对邻接逆向查询慢的特点,再构建一个逆邻接表与邻接表组合。这样就能够很容易的满足,谁关注了我,我关注了谁的需求。
深度和广度优先搜索:如何实现多维好友关系搜索
内容摘自极客时间,数据结构与算法之美